Search K
Appearance
我们大多数文本数据,都是以csv格式出现的
在python代码中,加载csv数据
from datasets import load_from_disk,load_dataset
# 这两个方法都可以
dataset = load_from_disk(r"D:/xxxx.csv")
print(dataset)我们把文本转化为模型可输入的数值,这个过程我们叫做编码 tf是tensorflow的tensor数据类型,pt是pythorch的tensor,np是numpy的数据类型
什么叫做bert模型 BERT模型代表了从静态词嵌入到transformer的编码器bert。gpt是transformer的解码器,这都是ai术语,就是一个特征提取,特征还原。
BertTokenizer 和 AutoTokenizer
为什么要加载预训练模型
训练时,损失在下降,精度在上升就没问题, 权重就是模型 疑问:预训练模型是用来做什么的,是 在预训练模型的基础上训练自己的数据吗,相当于基座这个意思? 判断过拟合得用验证集 模型微调的方式,步骤 模型内部只有下面这个三个会改变模型内部参数,其余操作不会改变 
为什么加入验证集,去判断过拟合
bert的语言字典vocab是给你开放出来了,正常情况下不会给你开放,字典内容加了数据,要进行重新训练,至少embedding模型要重新训练(微调)
模型有哪些结构?这个机构指的是神经元的组合方法,就是神经元以什么形式组合在一起的 当下主流的模型结构有:1、全连接MLP 2、RNN 循环神经网络(已经快消失了)3、CNN卷积4、图神经网络(它是一个拓扑结构) xw+b=h,变量是float32位数据,神经网络就是一堆数组构成的矩阵,做的就是数学计算
微调从大的方向分为?全量微调(所有模型都参与微调,就比如模型config发生改变)、局部微调、增量微调 增量微调只调增量部分,调的是w+b
模型训练增加精度的措施?1、保证数据的质量2、增加训练时长 在处理分类问题时,训练集中每个类别的数据量必须均衡,如果不均衡必须重采样
分类任务中,数据不均衡的问题处理方法? 使用imbalanced-learn的库,把少的变多的就是过采样,把多的变少的,就是欠采样 
什么时候为什么要特征和标签分类
如何更改模型的config文件实现自定义embedding,满足数据要求?训练模型时,如果模型的配置改动了,增量训练就无效了,不能在 torch.nograd(): 中,继续训练,就是不能冻结权重 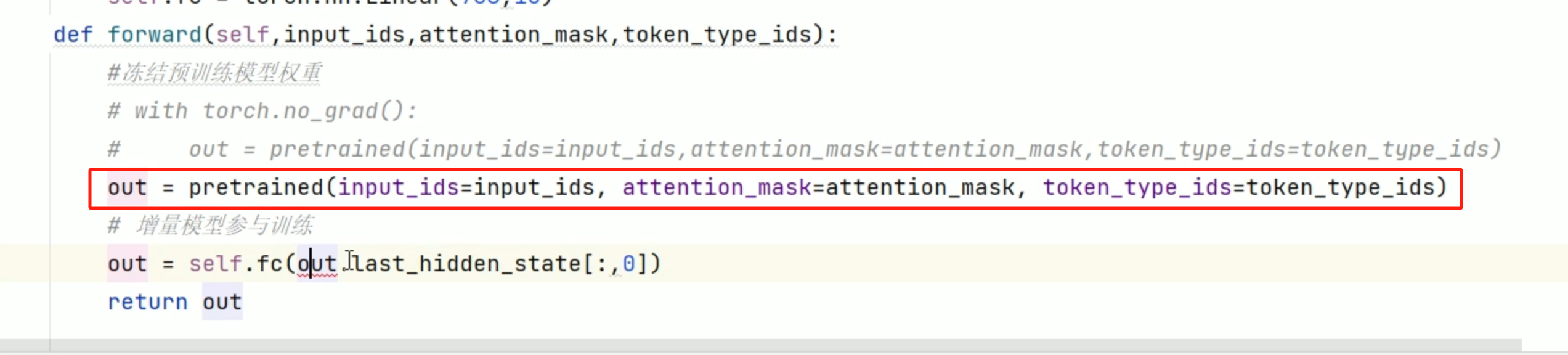
什么叫做冻结权重呢?就是不更改模型的参数
模型训练过程中,批次bacth_size(每次训练的数目)得试,批次越大越好,模型训练的效率越高,但是它和机器的显存有关(最优的时跑到显存90%左右)
bert是transform的编码器部分,可以利用其做文本分类
加载模型和分词器,这个分词器是什么东西,为什么加载分词器和模型的时候,要写路径,是下载到本地加载? 
通过pytorch创建数据集 模板:
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self):
pass
def __len__(self):
pass
def __getitem__(self,item):
passgpt生成文本的数据集的label,是没有的,也不能说是没有,是当前文字的前一个字 拿python模板举例
def __getitem__(self,item):
return self.lines[item]那生成类的精度是靠什么判断的? 相似度 文本内容生成的评估指标:客观评估、主管评估,用一些大的开源模型跑一下分
训练语言模型的优化器一般用什么 AdamW,为什么用它,因为它快,它简单,它里面的学习率可以自动调整
DataLoader的使用方法???
利用bert做文本分类的时候,我们用的是增量微调,这里的bert只做了个特征提取,意思就是 bert理解输入的含义就可以了
input_ids是啥来着
pytorch优化器学习率调整策略,有14种还是16种忘了,下面的这个是line线性策略,使得优化器在学习中更加稳定 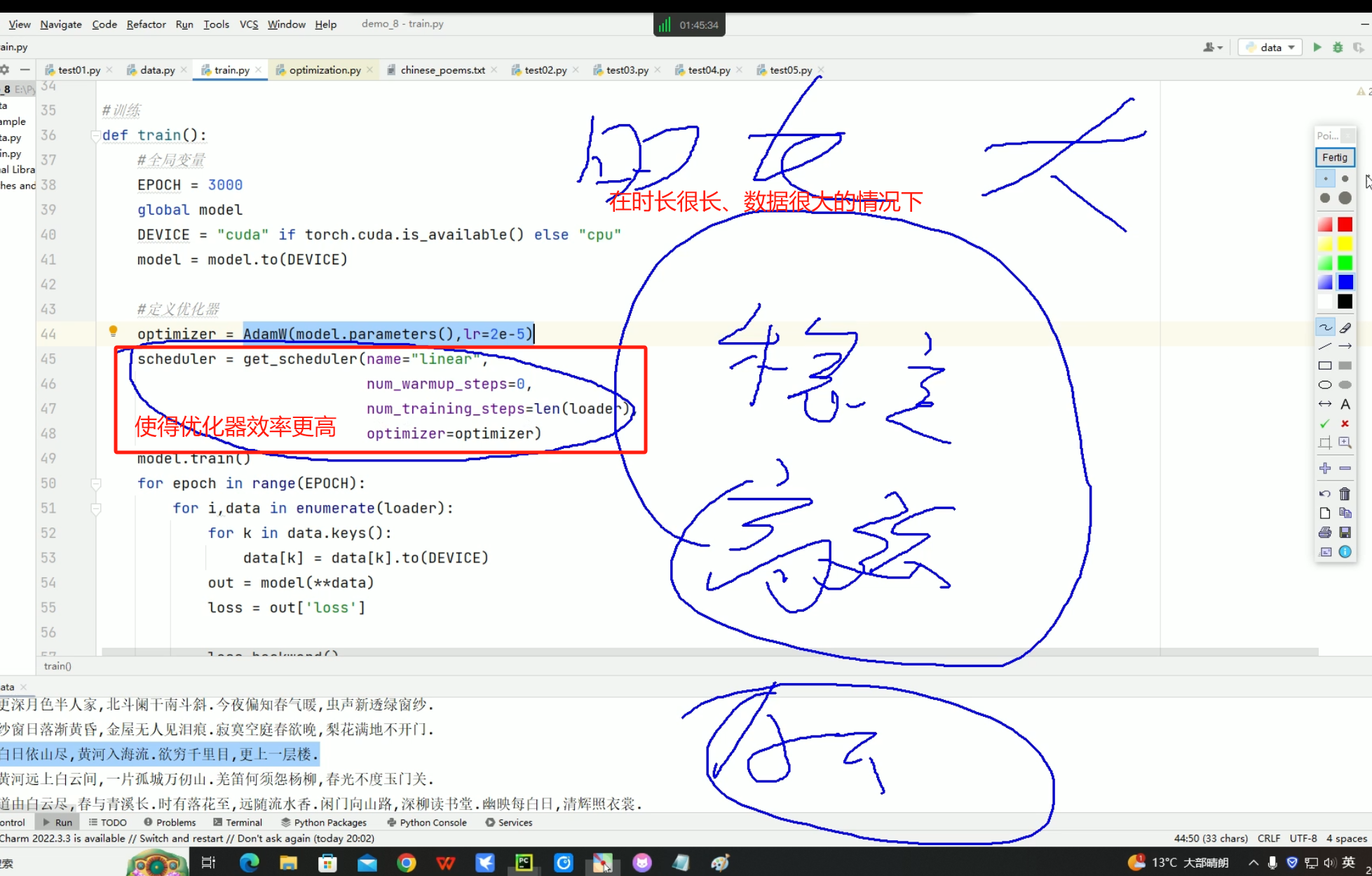
做nlp的时候,loss一般在1.5左右就比较好了
模型训练时候的加速方法,大模型微调的时候也用到,混合精度运算
本地测试transformer模型时候,不用使用 model.eval() ,因为transformer内部有调用,原因后面再查查
混合精度计算是一种能大幅度加速模型训练,并且减少显存占用,同时又不影响模型精度的技术,目前已经是大模型训练的默认配置。 计算机是怎样存储浮点数的呢? 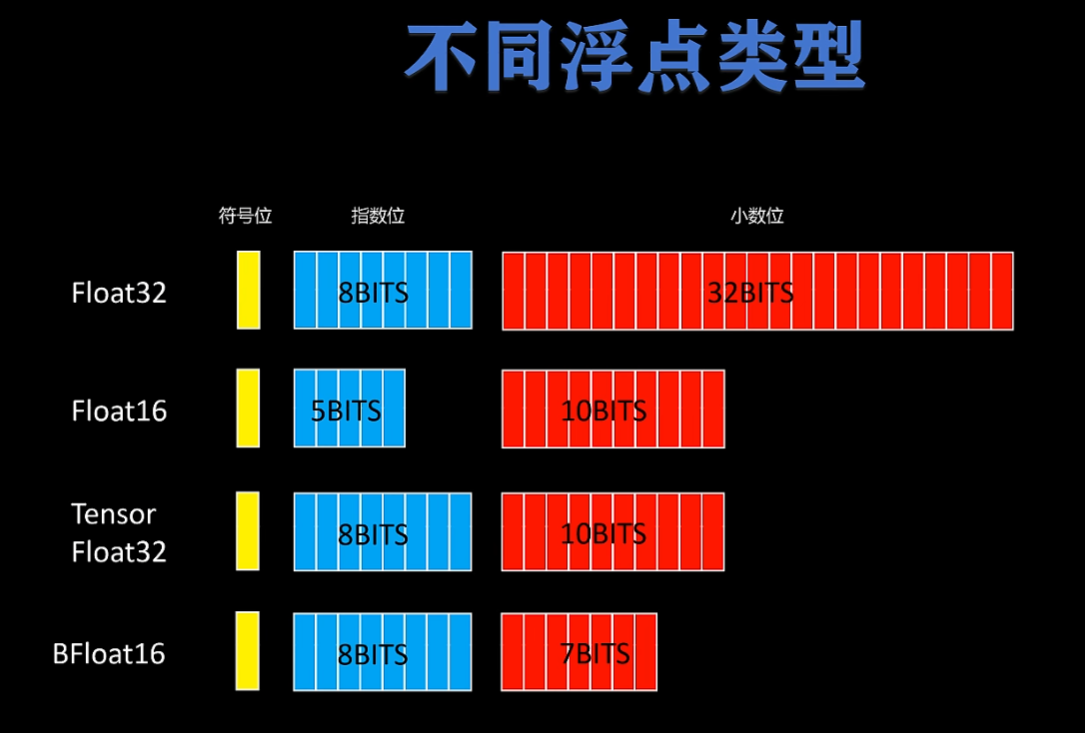 低精度带来的好处
低精度带来的好处  同时 低精度也带来了一些问题,float16的小数位置只有10位,太小的数,导致小数溢出为0了
同时 低精度也带来了一些问题,float16的小数位置只有10位,太小的数,导致小数溢出为0了 
tips:参数值相比较梯度来说都很大,就会有参数值吃掉梯度值的问题